
[Essay] 분산 시스템의 필요성
몇 년 전, 텍스트 마이닝 플랫폼을 운영하는 회사에서 근무한 적이 있다. 이 플랫폼(이하 'P')의 사용자는 브라우저를 통해 서비스에 접속하여 데이터 수집부터 분석에 이르는 파이프라인을 사용할 수 있었다. 시스템 구조는 여러 컴포넌트로 구성되어 있었으며, 사용자에게 UI/UX를 제공하는 웹 서버, 데이터 수집을 담당하는 크롤러, 전처리기, 사회연결망 분석을 수행하는 분석기 등이 주요 요소였다. 이 외에도 DB와 엘라스틱서치 같은 데이터 저장소들이 클라우드 상에서 실행되며 상호작용하는 SaaS 형태의 소프트웨어였다.
필자는 P의 전반적인 운영과 시스템 개선을 맡았다. 입사 후 시스템을 리버스 엔지니어링하면서 놀라움을 금치 못했는데, P가 실제로 서비스 중이라는 사실이 믿기 어려웠기 때문이다. 웹 서버는 사실상 프로토타입 수준이었을 뿐만 아니라, 데이터 수집, 전처리, 분석을 담당하는 수십 대의 서버가 짧은 주기로 DB를 풀링(polling)하면서 DB에 과도한 부하를 주고 있었다. 200%가 넘는 CPU 점유율을 목격했을 때의 아찔함은 지금도 생생하다.
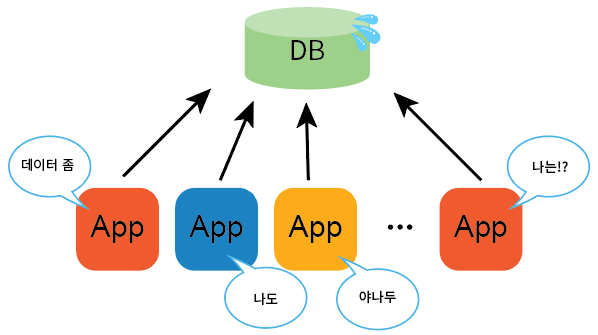
물론, 상태 확인만 필요한 경우라면 밀리세컨드 단위의 풀링 주기가 아니라는 전제 하에 풀링 자체는 나쁘지 않다. 그러나 서버를 점차 확장할 계획이라면 각 서버가 DB를 직접 풀링하는 방식은 성능과 확장성을 크게 저해하는 위험한 구조다. 당시 이러한 문제를 지적하는 사람은 없었다. 운영 인력이 부족해 시스템을 개선할 여력이 없었고, 서비스는 그럭저럭 운영되며 일정한 매출을 내고 있었기 때문이다.
입사 전에는 이 플랫폼이 훌륭하다고 생각했지만, 실제로 내부를 살펴본 후 큰 실망을 느꼈다. 확장성을 전혀 고려하지 않은 시스템이었으며, 이 상태로 운영을 지속하면 플랫폼이 무너지거나 VoC(고객 불만)에 압도당할 것이 뻔해 보였다.
사실, 이 문제는 분산 처리 관점에서 이미 연구가 충분히 이루어진 주제다. 핵심은 사용자가 많아지면서 증가하는 부하로 인해 발생하는 병목을 해결하는 것이다. 병목 구간을 개선하면 문제가 해결될 수 있다.
AS-IS 구조에서는 각 Worker 서버가 Select 쿼리를 통해 작업 정보를 DB에서 개별적으로 가져와야 한다. 이 방식은 병목을 유발할 가능성이 크다. 반면, TO-BE 구조에서는 Worker 서버들이 직접 쿼리하는 대신, Manager 서버가 모든 작업을 쿼리하고 유휴 상태의 Worker 서버에 작업을 전달(deliver)한다.
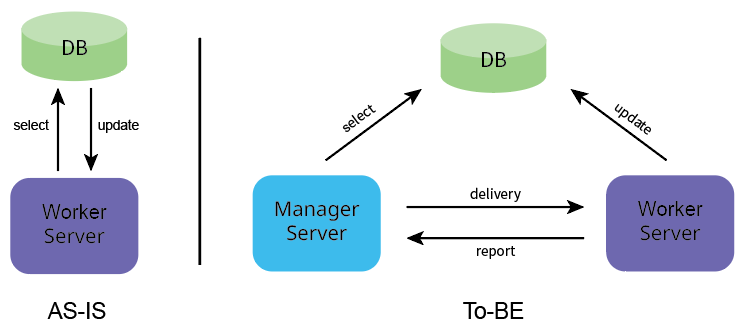
TO-BE 구조의 핵심은 상태 체크이다. Master 서버가 Worker 서버가 유휴한 지를 고려하지 않고 무작위로 작업을 전달한다면 구조 변경의 이득을 극대화할 수 없다. 예를 들어, Worker 서버가 작업 처리 중인데 Master 서버가 새로운 작업을 요청하면 손이 부족하니 결국 병목이 발생할 것이다. 병목 발생 시점을 늦추려면 Worker 서버 내 작업 처리 프로세스를 여러 개 두면 되지만 궁극적으로 병목은 피할 수 없다.
따라서 Master 서버는 다음의 getIdleWorkerCount와 같은 함수를 사용하여 주기적으로 Worker 서버의 유휴 상태를 체크하여 작업을 전달해야 하며, 유휴 상태의 프로세스가 없다면 다른 Worker 서버로 작업을 리다이렉트(redirect)해야 한다.
def getIdleWorkerCount(self, targetIP, targetPort):
with grpc.insecure_channel(f"{targetIP}:{targetPort}") as channel:
stub = EarthlingProtocol_pb2_grpc.EarthlingStub(channel)
response = stub.ReportIdleWorker(EarthlingProtocol_pb2.ReportRequest())
return response.idleCount
Worker 서버에는 Master 서버가 전달한 작업을 처리하는 1개 이상의 프로세스가 상시 동작한다. Worker 서버는 동작중인 모든 프로세스 작업 여부를 모니터링해야 하므로 스테이트풀(stateful)해야 한다. 스테이트레스(stateless)한 RESTful API은 통신 방법으로는 부적절하지만 소켓(socker) 통신은 적용해 볼만 한다. 하지만 Master 서버는 새로운 작업이 생성될 때만 Worker 서버로부터 헬스상태, 유휴상태를 보고 받으므로 양방향 통신이 필요하지 않고 연결 상태를 지속적으로 유지할 필요도 없다. gRPC는 스테이트풀(stateful)하면서 단방향으로 통신이 가능하므로 충분히 적절한 대응이 될 수 있다. gRPC에 대해서는 다음에 다시 한 번 설명하겠다.
Master 서버와 Worker 서버가 통신할 수 있도록 서로 간의 엔트리 포인트를 다음과 같이 지정해줘야 한다. 새롭게 추가된 Worker 서버가 있다면 서버의 엔트리 포인트를 반드시 추가해줘야 한다.
rpc:
...
manager:
address: '10.0.0.2'
port: 50051
assistant:
-
address: '10.0.0.3'
port: 50052
workers: [1000, 2000, 3000]
-
address: '10.0.0.4'
port: 50052
workers: [1000, 2000, 3000]
-
address: '10.0.0.5'
port: 50052
workers: [1000, 2000, 3000]
다음의 동영상은 DB에 등록된 작업이 Master 서버가 Worker 서버로 작업을 배정하고, Worker 서버가 작업을 처리하는 로그를 녹화한 것이다.
이상과 같은 분산 처리 시스템이 P에 적용한 후에는 CPU점유율이 40~50% 수준으로 떨어졌다. 무엇보다 Master 서버를 통해 Worker 서버를 중앙집중식으로 제어하고 로깅할 수 있게 되면서 수 개이던 Worker 서버를 순식간에 수십여개로 이상없이 늘려 뛰어난 확장성을 구현하게 되었다.
결과적으로 TO-BE 구조는 AS-IS 구조에 비해 CPU 점유율을 4배 이상 낮췄으며, 이와 함께 고객 문의도 대폭 줄어들었다. 하지만 이 개선은 단순히 성능만 향상시킨 것이 아니라, 운영 효율성 측면에서도 큰 변화를 가져왔다. 시스템의 안정성이 높아지고, 플랫폼이 더욱 확장 가능한 구조로 진화하면서, 서비스의 신뢰도 또한 상승했다.
이 경험을 통해 내가 깨달은 중요한 교훈은, 기술적인 문제는 종종 복잡한 해결책을 요구할 수 있지만, 그 해결책은 기본적인 시스템 설계와 구조적 접근에서부터 출발한다는 것이다. 무엇보다 중요한 것은 시스템의 성장을 염두에 두고, 확장성과 효율성을 고려한 설계를 하는 것이다.
비록 당시에는 여러 가지 어려움이 있었지만, 그 경험을 통해 기술적 문제 해결뿐만 아니라, 운영 환경에서의 실용적인 접근법을 배우게 되었다. 그리고, 이런 개선 작업이 결국에는 서비스의 품질을 높이고, 사용자 경험을 향상시키는 데 큰 기여를 한다는 사실을 다시 한 번 깨달았다. 이러한 경험들이 쌓여 더 나은 기술 리더로 성장하는 밑거름이 되었다고 생각한다.